# Introduction
Nowadays, Artificial Intelligence (AI) and Machine learning (ML) are everywhere. For example, movie recommendation systems suggest people what next movie to watch, based on their earlier selections; Google Photos recognizes people and identifies similar faces... The global artificial intelligence market size is expected to reach $169,411.8 million in 2025, growing at a CAGR of 55.6% from 2018 to 2025.
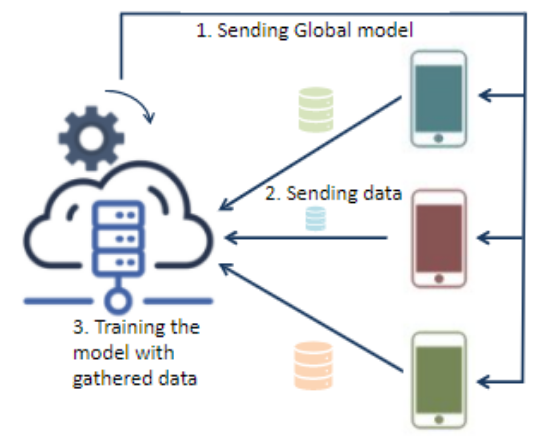
How are these ML algorithms learning to do such things? This is in fact with the help of our own data which is gathered on edge devices like our mobile phones and IoT devices. Figure 1 shows how traditional ML works: an organization/company maintains a global ML model; this model is sent to the devices (e.g. included in the distributed App); the model is used on the device to offer the organization/company's service; during this process, more data is gathered on each device; this new data is sent to the server; the server updates the global model using this new data; finally, the new model can be sent to the devices, e.g. as part of the next App update.
This learning by exploiting our data has several issues [Kairouz2019], the most prominent one being privacy leak. Other technical issues include the limited network bandwidth that the devices possess compared to the (huge) amount of data that has to be transferred (which cost is supported by the final user 😦). Another issue is the computational power which is needed to process this huge amount of data on the organization/company's side, which extends with the growing network. Privacy has become a crucial topic these days, as the users do not want to share their personal and sensitive information.
As an example, let us consider a word prediction system for mobile phone keyboards. Typing on a mobile phone keyboard includes private messages and passwords that the user types. No user would like to share such information with others. Virtual assistants, like Amazon Alexa and Microsoft Cortana, are built to make peoples' lives easier, but they have the ability to listen to everything said in a household and no one would want this information to be shared. As a consequence, communities have pushed politicians to create laws to protect their sensitive data (GDPR/CCPA). The traditional ML process is thus now impossible to deploy in practice in many countries.
A solution to still be able to develop ML-based applications, without violating user's privacy is known as Federated Learning (FL), and was first proposed by Google in 2017 [McMahan2017]. It is still a new and complex domain, with many challenges and has, thus, spread into many research questions and sub-fields of research, which make it not necessarily an easy task to enter the domain. To facilitate this task, on this blog, we will deliver a series of articles about FL, in order to give you a glimpse of what is and what are its current challenges:
This first article will briefly introduce what is FL,
A second article will present in more details and attempt to classify the different kinds of FL,
A final article will expose the trending topics and challenges of FL.
# What is Federated Learning?
As the main problem in traditional ML is the transfer of data towards the organization/company's servers (i.e. location where the model is trained), FL aims at taking the inverse approach: transferring the model and its training process to where the data lives (i.e. user's devices). The goal of FL is still to train a global model, but in a decentralized manner, across several devices, while maintaining a similar accuracy. FL allows the devices to keep their data private and only send updates of the global model to the organization/company's servers, after training it on their local data. As a consequence, the privacy of the data is better preserved and the cost of gathering and processing data is lowered.
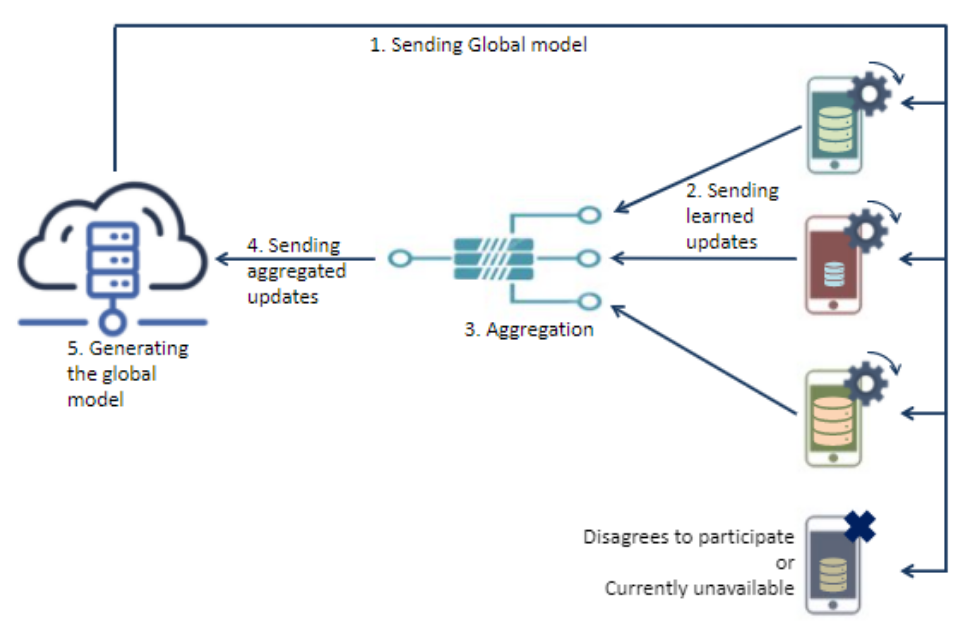
Let us illustrate FL with the same example of mobile keyboards as previously: Google has developed a word prediction system called Gboard which is developed for Android and iOS devices using FL. Gboard downloads the currently available model to the device, improves it using the data on the device and sends back the updates to Google's server where they are aggregated to form a new version of the model. Figure 2 depicts this process in more details: as a first step, Google server sends the initial model to a selection of Gboard users (those who agree/are available to participate in the training process). After that, each users' device further trains the model using their own data. Next, model updates are sent to the server. The server aggregates the model updates and sends the aggregated model back to the user devices for next iteration. When considering neural networks as models, model updates can be either the new weights, or the gradients.
The main advantage of FL is preserving the privacy of the clients. However, updated weights/gradients can still leak some sensitive information [Kairouz2019]. More protection can be added to data using some techniques like Trusted Execution Environment, Differential Privacy, Secure Multi-Party Computation and Homomorphic Encryption. Trusted Execution Environment (TEE), is a hardware solution to ensure there is no leak of information while doing computations either on the devices or the servers. Differential privacy (DP) consists of adding noise to a dataset so that the global statistics on the dataset remain almost the same, but making specific individual data impossible to recover (to a certain degree). Thus, if someone does ML on the modified dataset, she will obtain a very similar performance, but without leaking private data. It can be applied at the nodes and/or at the server. Secure Multi-Party Computation (SMPC) can be applied during the aggregation process. It is a cryptographic process that consists in modifying each individuals' data in such a way that when you aggregate the data, the modifications annihilate. Thus, the output of the process is public, but the inputs remain private. Homomorphic encryption allows to perform computations on encrypted (input) data and obtain an encrypted result, that can only be decrypted by the initiator of the computation. It has many advantages and could be used interestingly at many places to definitively solve the FL problem. Unfortunately, it has a large overhead (hundreds to thousands order of magnitudes slower!), so it is mainly used during inference for the moment. Indeed, as a single instance is transmitted for getting a prediction, DP cannot be used, as adding noise on a single input would ruin the prediction performance. By applying all these techniques at once in an FL setting, the data of individual users can actually be secured.
FL is very interesting for various reasons. First, it is the only means to continue doing ML (i.e. provide rich services to end-users), without breaking their privacy and local laws. As many countries have legal barriers to share individual data with other countries, FL allows maintaining large international business without adding the burden of training ML models only on national data (localizing each App can be interesting, but getting more - international - helps ML model creating better generalizations). Since part of the computations are done on the edge devices, the organizations/companies do not need to scale their data/compute centers drastically with the size of their user base. Similarly, instead of transferring and storing all the raw user data, only the model updates need to be transferred. Model updates are generally smaller than raw data. However, FL will involve several rounds to achieve comparable performance as with traditional ML, thus there's a trade-off to find between the number of rounds (i.e. multiple transfers of model updates) and size of initial raw data. Finally, since FL does not require to transfer individual raw data, it allows competitors to create a performant shared/global model without exchanging user data. New markets emerge, particularly in Healthcare, where hospitals/clinics collaborate to create performant ML models (disease detectors, etc.), learnt on huge amounts of data, without revealing very sensitive patient data, and Banking, where private banks and governments can collaboratively detect bad behaviours (tax fraud, money laundering, etc.) again, without revealing very sensitive citizen/tax-payer data. Finally, in some forms of FL, it is even possible to collaboratively build parts of a ML model (a.k.a. Split Learning, e.g. first layers, like convolution or representation layers) without sharing the ultimate goal (last layers, e.g. classification) of the model. It is useful in applications with even stricter privacy needs, for Multi-Task Learning, etc.
# Conclusion
In this article we discussed what Federated Learning (FL) is, how it works and some of its advantages.
For scientific researchers, there are still some open issues and challenges in this field. As we have seen, FL is composed of several steps (model initialisation, device selection, aggregation, etc.) and almost each of them is susceptible of multiple variations, either due to the particular settings of the application domain (e.g. distribution of the data within the devices) or to better solve a particular problem (like fair device selection, or more private/secured aggregation...).
*Our [second article](./2021-05-05-federated-learning-taxonomy.md) in this series will discuss much of these possibilities and try to achieve a **taxonomy** of the FL variants.*
There are also other more practical issues and challenges. Efficiency is one of them, where the accuracy increases with the runtime increases. Model convergence becomes hard when working with non-IID data. Privacy-preserving is still a problem as the decentralized process of FL is more open to bad behaviours (voluntary, like attacks, or involuntary, like errors or bugs) in many places and in many forms, e.g. where the server and/or other nodes try to "reverse" the devices model updates or when a device "injects" bad updates during the aggregation. Also, applying any ML model other than Neural networks is complicated (e.g. What is model averaging for Decision Trees?).
*Our [third & final article](./2021-05-05-federated-learning-challenges.md) will present the current **open issues and challenges** in more details*.
# References
[McMahan2017] H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. Agüera y Arcas, "Communication-Efficient Learning of Deep Networks from Decentralized Data", Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), Volume 54, 2017.
[Kairouz2019] P. Kairouz, H.B. McMahan, B. Avent, A. Bellet, M. Bennis, A.N. Bhagoji, K. Bonawitz, Z. Charles, G. Cormode, R. Cummings, and R.G. d'Oliveira, "Advances and open problems in federated learning", Foundations and Trends in Machine Learning, Volume 4 Issue 1, 2019.